Lines of Code Are Still a Liability, Even When AI Writes Them

Real engineering is about solving problems efficiently, not generating a mountain of technical debt.
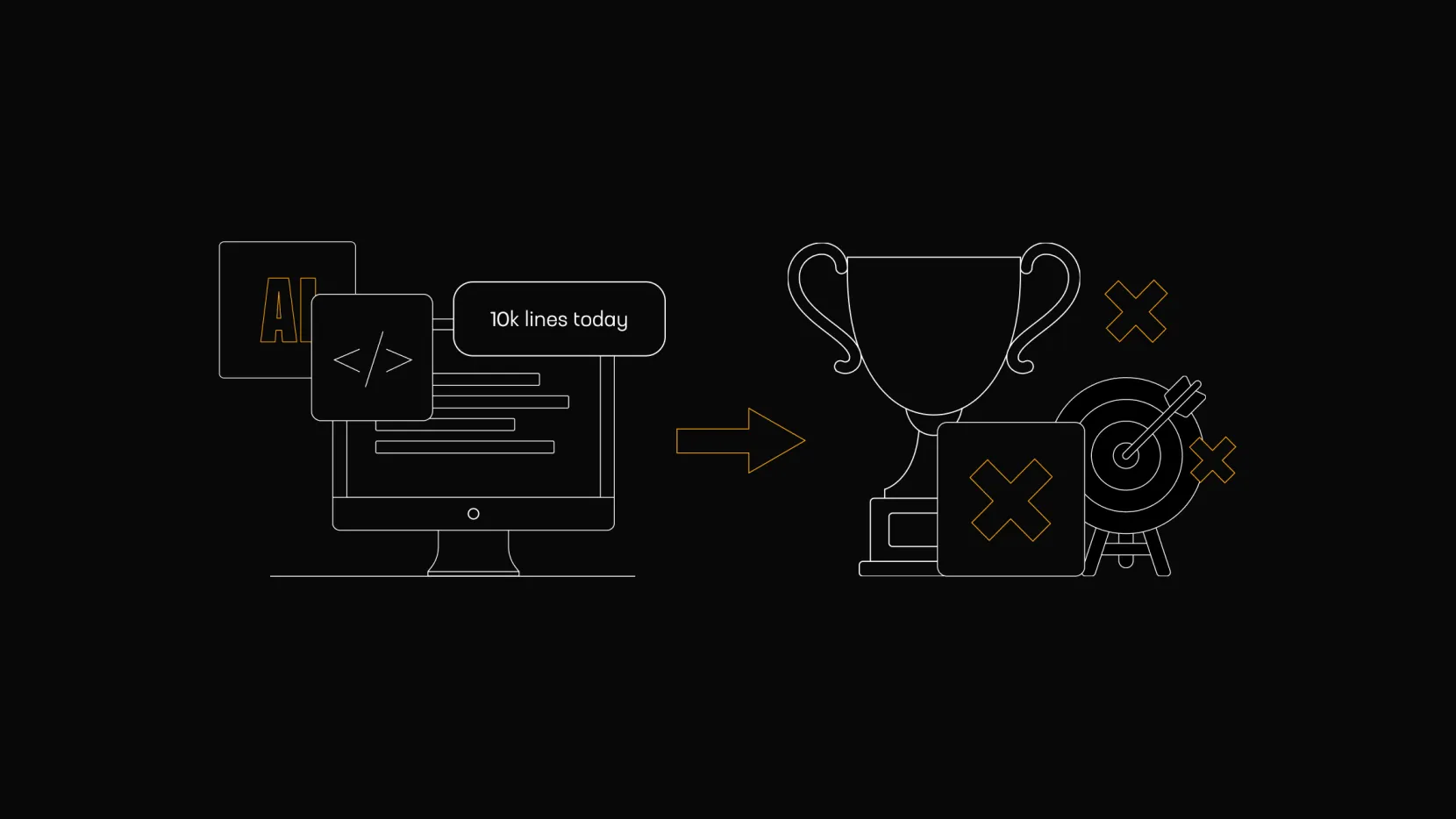
I keep seeing the same pattern on LinkedIn, X, and dev forums: flexing with massive code diffs, token burn reports, or claims like “10000 lines shipped today with AI.” Are people treating volume as an….achievement? Or proof of progress?
As someone who has spent years building and then desperately maintaining production systems, I have to call it what it is: we are repeating a very old mistake, just with shinier tools.
Generating a massive amount of code just because you can doesn’t mean you are building a good product. Lines of code aren’t a trophy; they are overhead.
The Permanent Tax of Code
Before AI, the sheer effort of typing and structuring code acted as a natural filter. It forced developers to consider whether a feature was really necessary or whether a simpler solution existed.
AI has removed that friction. Writing code is incredibly easy now. But while the friction of writing code is gone, the friction of maintaining it remains exactly the same.
Every additional line you introduce carries a permanent tax. It needs reading, testing, documenting, refactoring when requirements change, and debugging when it breaks. The cost compounds over years, not days. Code is just the cost of doing business. The goal of software engineering has never been to write code; it has been to solve problems.
The Code Review Illusion
Anyone who was reviewing code before the AI boom knows that it is humanly impossible to properly review thousands of lines of code at once. So, when someone generates a massive PR in a short period, it is pretty clear that those lines were never genuinely reviewed.
Personally, I tend to reject merge requests that have 1,000+ changes. My preference is around 100 lines. Even a 100-line PR takes time to evaluate if the review is actually taken seriously. Dropping a 10000-line AI generation into a codebase isn’t productivity, it’s negligence.
From what I’ve seen in real deployments, a sentiment increasingly echoed in dev communities, the AI coding lifecycle follows a very consistent, painful pattern:
- Generation feels incredibly productive.
- Stabilization and debugging eat up most of the initial time gains.
- Long-term maintenance becomes the real bottleneck.
Seniority Means Less Code (Even for AI)
The higher I climbed the senior career ladder, the less code I wrote. There are weeks when, even on tasks solved programmatically, I will write at most a few lines. Complex, deep problems usually require modifying only a small part of the core logic, not dumping a thousand lines of boilerplate. When you see someone generating a massive amount of code to solve a single problem, you instantly know it’s unnecessary bloat.
Naturally, this exact same rule applies to AI.
I use Cursor for AI-augmented development, and I’ve noticed a direct correlation between how advanced an AI model is and how much code it generates:
- Auto (Composer 1.0 / 1.5): Spits out the most lines of code. It tends to overengineer and adds unnecessary comments that describe what the code does rather than why.
- Gemini 3 / 3.1 Pro: Generates almost the exact right amount of code. No massive bloat.
- Opus 4.5 / 4.6: Similar to Gemini, occasionally even slightly more concise and accurate.
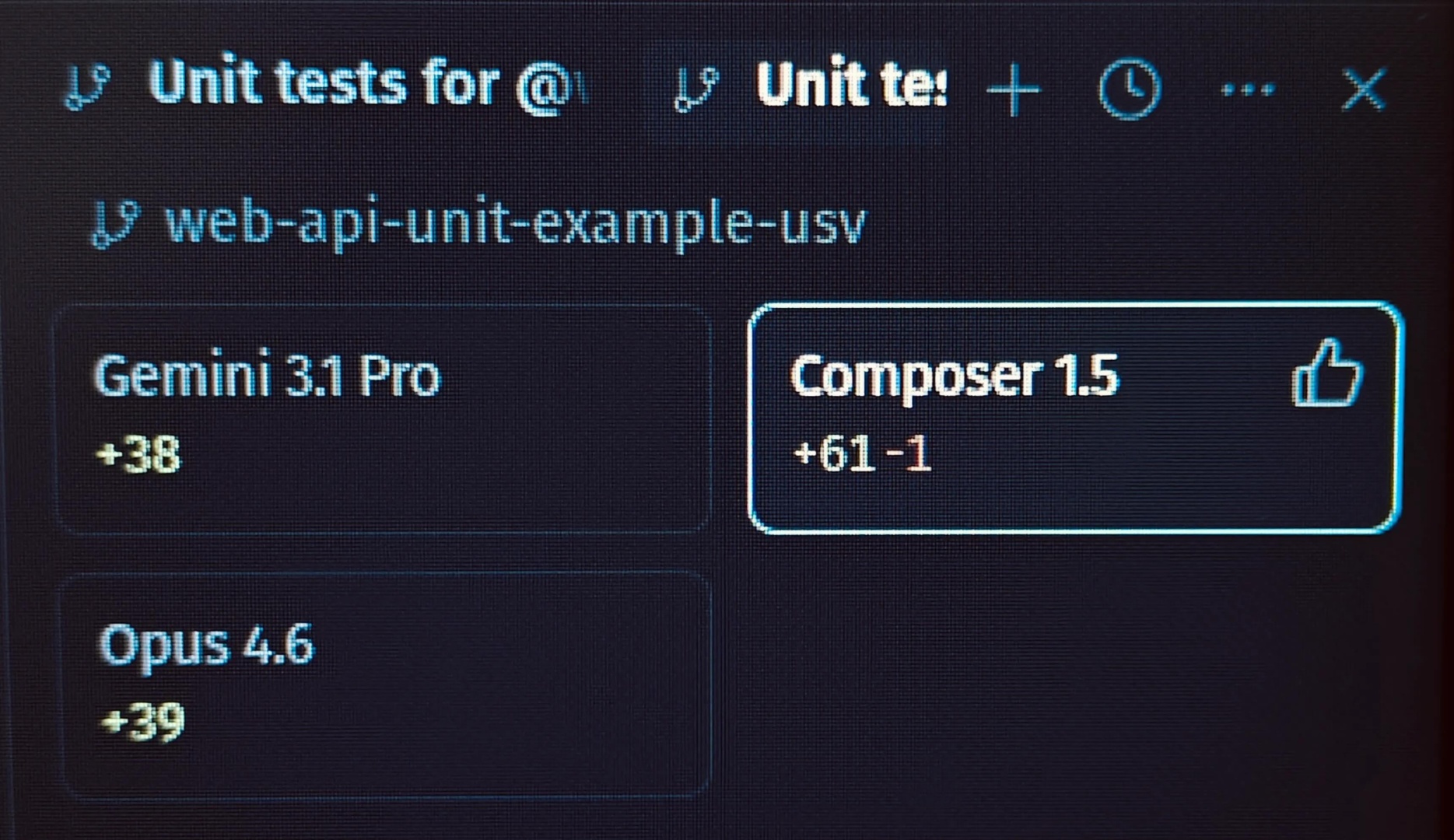
It correlates perfectly with human developers: the “more senior” the model, the less code it writes.
The Real Flex for 2026
The sign of a great developer hasn’t changed, even with better autocomplete. A great engineer is still the one who can look at a complex problem and solve it with the least amount of code possible. It’s the architect who removes 5,000 lines of spaghetti code and replaces them with a clean, 500-line solution. Efficiency, readability, and simplicity are what keep a production environment stable. Volume does the exact opposite.
We should celebrate outcomes, not input volume. A tiny, battle-tested service that handles real traffic quietly is worth infinitely more than a sprawling AI-generated monolith that looks impressive on a GitHub contribution graph.
So here’s my unpopular take for 2026: stop bragging about how much code AI wrote for you.
Start sharing how little you ultimately kept after review, testing, and real-world use. Show me the diff where you aggressively deleted AI output. Show me the architecture diagram that stayed simple. That is the flex that actually matters.